[Spring/SpringBoot] 채팅방 쿼리 개선기 | JPA(Hibernate)+Mysql에서 BulkInsert(벌크 인서트) | Native Query, JDBC Template 비교하기
개요
채팅방에서 사용자를 참여시킬때 기존의 로직에서는 한명씩 참여시켰습니다. 이로 인해
사용자를 찾고, 참여시키는 로직이 중복됨에 따라
1. 로직적으로 2. 쿼리적으로 성능을 개선하여, 부하를 줄이도록 서비스의 성능을 개선하였습니다.
한편 이때 bulk insert를 구현해보면서 mysql 과 JPA의 조합에서 어떻게 하면 구현이 가능한지 알아보았습니다.
기존 로직
사용자가 한 명씩 채팅방에 참여한다.
joinRoom 메소드에서 사용자를 한명씩 찾아서 그에 필요한
ChatRoomMessageCounter와 같은 객체들을 찾아서 저장하는 로직이 중복되고 있습니다.
여기에서 로직적으로 개선 가능한 부분은
1. 사용자를 찾을 때 쿼리에 IN 절을 사용하여 한번의 쿼리로 유저 검색이 가능하다
2. 참여하는 채팅방과 사용자가 몇번 메시지 까지 읽었는지 관리하는 ChatRoomMessageCounter객체는 공통으로 사용이 가능하다 -> 같은 객체를 사용해도 되기때문에 사용자마다 검색할 필요 없음
3. 아래와 같이 채팅방에 몇명이 있는지 저장하는 로직또한 1씩 증가가 아닌 사람 수만큼 한번만 수정 가능.
chatRoom.setUsedMemberCount(chatRoom.getUsedMemberCount() + 1); @Transactional
@Override
public ChatRoomDTO joinRoom(JoinChatRoomCommand command) {
// 1. UserEntity 검색
UserEntity user = userRepository.findById(command.getUserId())
.orElseThrow(() -> new NotFoundException("User not found"));
// 2. ChatRoomEntity 검색
ChatRoomEntity chatRoom = chatRoomRepository.findById(command.getRoomId())
.orElseThrow(() -> new NotFoundException("ChatRoom not found"));
if (chatRoomUserRepository.findByUserAndChatRoom(command.getUserId(), command.getRoomId()).isPresent()) {
// 이미 참여한 경우
return new ChatRoomDTO(chatRoom.getId(), chatRoom.getTitle());
}
// get ChatRoomMessageCounter
ChatRoomMessageCounter chatRoomMessageCounter = chatMessageCounterRepository.findByRoomIdForRead(command.getRoomId())
.orElseThrow(() -> new NotFoundException("ChatRoomMessageCounter not found"));
// 아닌 경우 ChatRoomUserEntity 생성
ChatRoomUserEntity chatRoomUser = new ChatRoomUserEntity();
chatRoomUser.setUser(user);
chatRoomUser.setChatRoom(chatRoom);
chatRoomUser.setLastReadMessageId(chatRoomMessageCounter.getLastMessageId());
chatRoomUserRepository.save(chatRoomUser);
chatRoom.setUsedMemberCount(chatRoom.getUsedMemberCount() + 1);
chatRoomRepository.save(chatRoom);
return new ChatRoomDTO(chatRoom.getId(), chatRoom.getTitle());
}
개선1
사용자를 List로 받아 채팅방에 참여한다.
사용자 id를 List로 받아
1. UserEntity를 한번의 쿼리로 조회
2. 채팅방과 메시지 카운터도 한번만 조회
3. 이미 참여한 유저를 제외하고 리스트에 담아서 saveAll
@Transactional
@Override
public ChatRoomDTO joinRoom(JoinChatRoomCommand command) {
// 1. UserEntity 검색
List<UserEntity> users = userRepository.findByIdIn(command.getUserIds());
// 선택한 유저가 없는 경우 Exception
if (users.size() != command.getUserIds().size()){
throw new NotFoundException("User not found");
}
// 2. ChatRoomEntity 검색
ChatRoomEntity chatRoom = chatRoomRepository.findById(command.getRoomId())
.orElseThrow(() -> new NotFoundException("ChatRoom not found"));
// 3. 이미 참여한 사용자
List<ChatRoomUserEntity> existingChatRoomUsers = chatRoomUserRepository.findByUserIdsAndChatRoomId(command.getUserIds(), command.getRoomId());
Set<Long> existingUserIds = existingChatRoomUsers.stream()
.map(entity -> entity.getUser().getId())
.collect(Collectors.toSet());
// 4. 새롭게 참여하는 사용자
List<UserEntity> newUsers = users.stream()
.filter(user -> !existingUserIds.contains(user.getId()))
.toList();
// get ChatRoomMessageCounter
ChatRoomMessageCounter chatRoomMessageCounter = chatMessageCounterRepository.findByRoomIdForRead(command.getRoomId())
.orElseThrow(() -> new NotFoundException("ChatRoomMessageCounter not found"));
if (!newUsers.isEmpty()) {
List<ChatRoomUserEntity> newChatRoomUsers = newUsers.stream()
.map(user -> {
ChatRoomUserEntity cru = new ChatRoomUserEntity();
cru.setUser(user);
cru.setChatRoom(chatRoom);
cru.setLastReadMessageId(chatRoomMessageCounter.getLastMessageId());
return cru;
})
.collect(Collectors.toList());
chatRoomUserRepository.saveAll(newChatRoomUsers);
chatRoom.setUsedMemberCount(chatRoom.getUsedMemberCount() + newUsers.size());
chatRoomRepository.save(chatRoom);
}
return new ChatRoomDTO(chatRoom.getId(), chatRoom.getTitle());
}
개선점
-> 사용자마다 반복되는 로직과 쿼리들이 확연히 감소하였습니다.
하지만 saveAll을 통해 insert 로직은 간소화 하였지만, 실제로 insert 쿼리는 유저만큼 나가게 되는 것을 확인할 수 있었습니다.
여전히 남아있는 문제점 (하이버네이트와 mySql 조합의 한계)
JPA 에서 saveAll 메소드를 사용하더라도, 실제로 저장할때는 insert 쿼리가 합쳐서 나가는 것이 아니라 한번씩 나가게 됩니다.
그렇다면 벌크 인서트를 통해 한번에 저장할 수 있는 로직을 구현하면 어떨까? 라고 생각하였습니다.
`INSERT INTO test_table (name) VALUES ('Alice'), ('Bob'), ('Charlie'):`
이런식으로 multi-row insert를 적용해보기로 하였습니다.
하지만 하이버네이트의 identity라는 키 발급 방식에서 문제를 발견했습니다.
현재 프로젝트에서는 키 제너레이션 방식으로 identity를 사용하고 있고, 이러한 설정은 multi row를 insert할때 hibernate에서 각 객체의 id를 확인할 수 있는 방법이 없어, bulk insert가 불가능합니다.
하이버네이트의 IDENTITY 전략의 동작 방식
- ID 값 생성 시점
IDENTITY 전략은 데이터베이스에 행을 삽입할 때, 각 행의 AUTO_INCREMENT 값이 즉시 생성됩니다. 즉, Hibernate는 행이 삽입될 때마다 데이터베이스로부터 생성된 ID 값을 받아와야 합니다. - Hibernate의 ID 관리
Hibernate는 엔티티의 ID 값을 먼저 설정해야 객체를 관리할 수 있습니다. IDENTITY 전략에서는 ID가 데이터베이스에서만 생성되므로, 매 행마다 별도의 INSERT 문을 실행하고, 각 행의 ID 값을 데이터베이스에서 가져와야 합니다. - Multi-row INSERT의 문제
다수의 행을 한 번에 삽입하는 multi-row INSERT는 데이터베이스에서 각 행의 ID를 반환받는 구조가 아니기 때문에, Hibernate가 ID 값을 적절히 관리할 수 없습니다.
예를 들어, 아래와 같은 SQL을 실행하면:데이터베이스는 각 행의 AUTO_INCREMENT 값을 생성하지만, Hibernate는 이를 알 방법이 없습니다. Hibernate는 각 엔티티의 ID를 개별적으로 설정해야 하므로, 이를 위해 각 행마다 별도의 INSERT 문을 실행합니다
한편 그렇다면 사용할 id를 한번에 끌고와서 저장하여 id를 설정하는 방식을 사용하면 되는데,
이렇게 하는 경우에도 고려해야할 만한 사항이 있습니다.
그렇다면 다른 Key generation 옵션을 사용하면 어떨까?
1 . GenerationType.SEQUENCE
- 시퀀스 객체로 id생성
- 하지만 MySql은 시퀀스를 지원하지 않는다 -> 현재 프로젝트에서는 MySql을 사용중
- 낭비될 수 있는 시퀀스
ex) allocationSize=50일 때, 150까지 미리 가져왔지만, 10번까지 사용 후 애플리케이션이 중단되면 1150은 낭비
2. GenerationType.TABLE
- id를 생성하기 위한 테이블을이 필요하다
- 여러 스레드가 동시에 테이블에서 ID 값을 가져오려고 할 때, 잠금 문제가 발생할 수 있다 -> 동시성이 떨어짐
이러한 이유로 multi row insert 쿼리를 직접 작성하는 것으로 개선을 해보기로 하였습니다.
직접 쿼리를 작성하는 방식은 JPA 에서 쿼리를 작성할수 있는 방법과, JDBC template의 preparedstatement를 사용해서 쿼리를 작성하는 것 두개를 비교해 보겠습니다.
개선2-1안
유저 참여 쿼리를 NativeQuery를 통해 bulk insert한다.
// (1) INSERT 구문 생성
// 예: INSERT INTO chat_room_user (user_id, chat_room_id, last_read_message_id)
// VALUES (:userId0, :roomId, :lastReadMessageId),
// (:userId1, :roomId, :lastReadMessageId), ...
StringBuilder sqlBuilder = new StringBuilder();
sqlBuilder.append("INSERT INTO chat_room_user (user_id, chat_room_id, last_read_message_id) VALUES ");
for (int i = 0; i < newUsers.size(); i++) {
sqlBuilder.append("(:userId").append(i).append(", :roomId, :lastReadMsgId)");
if (i < newUsers.size() - 1) {
sqlBuilder.append(",");
}
}
// (2) Native Query 객체 생성
Query insertQuery = entityManager.createNativeQuery(sqlBuilder.toString());
// (3) 파라미터 바인딩
for (int i = 0; i < newUsers.size(); i++) {
insertQuery.setParameter("userId" + i, newUsers.get(i).getId());
}
insertQuery.setParameter("roomId", chatRoom.getId());
insertQuery.setParameter("lastReadMsgId", chatRoomMessageCounter.getLastMessageId());
// (4) 실행
insertQuery.executeUpdate();
개선2-2안
유저 참여 쿼리를 JDBCTemplate을 통해 bulk insert한다.
package com.example.chatserver.repository;
import com.example.chatserver.entities.ChatRoomEntity;
import com.example.chatserver.entities.UserEntity;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Repository;
import java.util.ArrayList;
import java.util.List;
@Repository
public class ChatRoomUserJdbcRepository {
private final JdbcTemplate jdbcTemplate;
public ChatRoomUserJdbcRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public void insertChatRoomUserMultiValues(List<UserEntity> newUsers,
ChatRoomEntity chatRoom,
Long lastMessageId) {
if (newUsers == null || newUsers.isEmpty()) {
return;
}
// 1) INSERT 구문 생성
// 예: INSERT INTO chat_room_user (user_id, chat_room_id, last_read_message_id) VALUES (?,?,?),(?,?,?),... 형태
StringBuilder sqlBuilder = new StringBuilder();
sqlBuilder.append("INSERT INTO chat_room_user (user_id, chat_room_id, last_read_message_id) VALUES ");
for (int i = 0; i < newUsers.size(); i++) {
sqlBuilder.append("(?,?,?)");
if (i < newUsers.size() - 1) {
sqlBuilder.append(","); // 마지막 레코드 전까지는 콤마로 구분
}
}
// 2) PreparedStatement 에 바인딩할 파라미터 목록 생성
// user_id, chat_room_id, last_read_message_id 순서대로
List<Object> params = new ArrayList<>();
for (UserEntity user : newUsers) {
params.add(user.getId());
params.add(chatRoom.getId());
params.add(lastMessageId);
}
// 3) 생성한 쿼리와 파라미터를 사용하여 실행
jdbcTemplate.update(sqlBuilder.toString(), params.toArray());
}
// 기존 코드 - chat_room.used_member_count 컬럼 업데이트 예시
public void updateChatRoomUsedMemberCount(Long chatRoomId, int size) {
String updateSql = """
UPDATE chat_room
SET used_member_count = used_member_count + ?
WHERE id = ?
""";
jdbcTemplate.update(updateSql, size, chatRoomId);
}
} @Override
@Transactional
public ChatRoomDTO joinRoom(JoinChatRoomCommand command) {
// 1. UserEntity 검색 (JPA)
List<UserEntity> users = userRepository.findByIdIn(command.getUserIds());
if (users.size() != command.getUserIds().size()) {
throw new NotFoundException("User not found");
}
// 2. ChatRoomEntity 검색 (JPA)
ChatRoomEntity chatRoom = chatRoomRepository.findById(command.getRoomId())
.orElseThrow(() -> new NotFoundException("ChatRoom not found"));
// 3. 이미 참여한 사용자 (JPA)
List<ChatRoomUserEntity> existingChatRoomUsers =
chatRoomUserRepository.findByUserIdsAndChatRoomId(command.getUserIds(), command.getRoomId());
Set<Long> existingUserIds = existingChatRoomUsers.stream()
.map(entity -> entity.getUser().getId())
.collect(Collectors.toSet());
// 4. 새롭게 참여하는 사용자
List<UserEntity> newUsers = users.stream()
.filter(user -> !existingUserIds.contains(user.getId()))
.toList();
// 5. ChatRoomMessageCounter 조회 (JPA)
ChatRoomMessageCounter chatRoomMessageCounter =
chatMessageCounterRepository.findByRoomIdForRead(command.getRoomId())
.orElseThrow(() -> new NotFoundException("ChatRoomMessageCounter not found"));
// 6. 새로 참여할 유저 있으면 JDBC로 INSERT / UPDATE
if (!newUsers.isEmpty()) {
chatRoomUserJdbcRepository.insertChatRoomUserMultiValues(newUsers, chatRoom, chatRoomMessageCounter.getLastMessageId());
chatRoomUserJdbcRepository.updateChatRoomUsedMemberCount(chatRoom.getId(), newUsers.size());
}
// 7. DTO 반환
return new ChatRoomDTO(chatRoom.getId(), chatRoom.getTitle());
}
실제 성능 테스트 결과
성능 테스트는 Jmeter를 통해 간단하게 진행해보았습니다.


테스트 시나리오 2가지
- 3000명의 사람이 1초 동안 한번에 1회 자기자신을 포함한 5명의 유저로 채팅방을 생성합니다.
- 3000명의 사람이 1초 동안 한번에 1회 자기자신을 포함한 20명의 유저로 채팅방을 생성합니다.
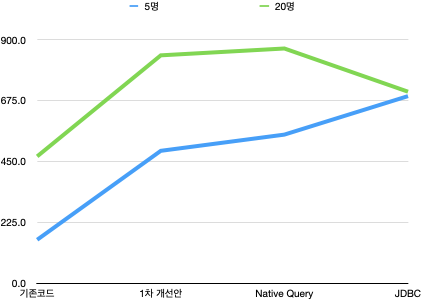
- 처리율 향상:
- 5명 채팅방의 경우, 기존 대비 85.1% 처리율 향상(Native Query).
- 20명 채팅방의 경우, 기존 대비 331.4% 처리율 향상(JDBC Template).
- 응답 시간 및 안정성:
- 5명 채팅방: Native Query 방식이 가장 낮은 응답 시간을 기록
- 20명 채팅방: JDBC Template 방식이 안정성과 처리량에서 가장 좋은 결과
이렇게 두개의 응답이 각 채팅방마다 성능 지표가 다르게 나타났는데요, 결론적으로
간단한 벌크 인서트 시에는 Native Query를, 대규모 데이터 처리에서는 JDBC Template를 사용하는 것이 더 유리하다는 지표를 볼 수 있었습니다.
왜 이런 결과가 나왔는지 곰곰히 생각해보니
20명에서 JDBC Template가 더 빨랐던 이유?
- JDBC Template는 순서 기반 파라미터 바인딩을 통해 한 번의 바인딩 작업으로 대량 데이터를 처리합니다.
- 반면 Native Query는 이름 기반 파라미터를 생성하고 각각 바인딩해야 합니다.
따라서 데이터가 많아질수록 바인딩을 두번해야하는 Native쿼리의 경우에는 성능 저하 발생하지 않았을까 하는 생각이 있습니다.
더 나아가기
완벽한 부하테스트가 어렵다
테스트를 진행하면서 완전히 똑같은 환경에서 테스트를 진행하기위해 매번 애플리케이션을 새롭게 시작하고, DB의 데이터도 새롭게 지우고 테스트를 진행하였습니다.
하지만 여러번의 test를 통해서 cold start의 문제를 발견할 수 있었습니다. 아예 처음 API를 받는 서버의 경우에는 첫 몇개의 요청들이 처리되지 못하는 모습을 보였습니다. 미리 시작해둔 application의 경우에는 api를 처리하기 위한 데이터들이 모두 로딩되어있어 초기 에러율이 발생되지 않았습니다.
따라서 앞으로의 테스트는 웜업 기능을 추가하거나, cold start가 일어나지 않도록 일정 수의 요청을 보내놓고 진행해보아야겠습니다.
무조건 빠른 것만이 정답일까
아래의 두개의 개선안은 안되는 multi row insert를 위해서 직접 쿼리를 작성합니다. 따라서 성능은 무조건 개선이 되지만, 이러한 쿼리의 경우에는 유지보수가 어렵고 가독성이 떨어지는 단점이 있습니다.
로직상의 성능개선까지만 실제 서비스에서는 구현을 하고, QueryDsl을 사용해서 더 안전하게 쿼리를 작성하는 방법까지도 함께 고려해보아야겠습니다.